线性回归模型
0x00
这篇短文主要讲Scikit-learn下面的几种线性模型使用,也是比较熟悉和常用的几个:
- 普通线性回归
- 逻辑回归
0x01逻辑回归
这个模型是最简单也是最基础的一个模型,通过求际观测数据和预测数据之间的最小差方和来拟合方程,一般可以用来。单地做些数据预测。公逻辑也是回归式表示如下:

下面讲个简单的例子,先生成一些随即数据,数据根据一个线性方程±一些随即数得到
import numpy as np
x = np.arange(40)
delta = np.random.uniform(-50, 50, size=(40,))
w = np.random.randint(-10, 10)
y = w * x + delta
我们用Scikit-learn的LinearRegression模型来对数据进行拟合
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit(np.array(x).reshape(-1, 1), y)
LinearRegression把数据fit()进去后就会进行拟合,通过调用reg.coef_可以获取到各个特征值系数(除了θ0),常数系数(也就是一般公式里面的θ0)在Sklearn叫截距系数reg.intercept_
下面我们把上面的数据和拟合好的函数用matplotlib画出来看看
from matplotlib import pyplot as plt
fig, ax = plt.subplots()
ax.plot(x, y, 'o', label='Samples') #描绘数据集
_XX = np.array([min(x), max(x)])
XX = np.ones((2, 2))
XX[:, :-1] = _XX.reshape((2, 1))
YY = np.array([*reg.coef_, reg.intercept_]).dot(np.array(XX).T)
ax.plot(_XX, YY) #描绘拟合好的函数
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
结果如下:
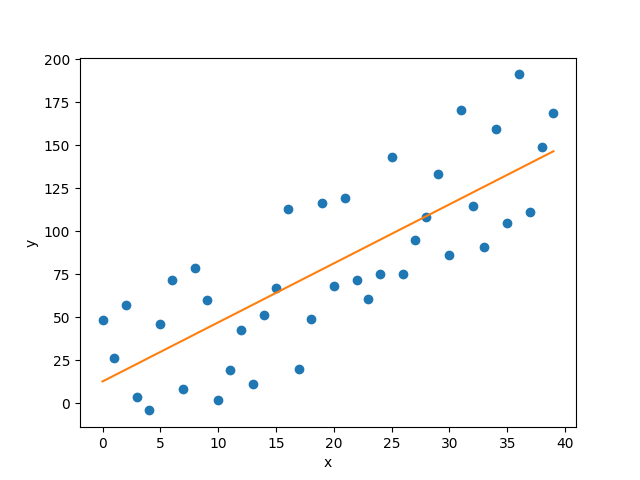
对于一般的线性回归问题,可以用这种方法简单地进行拟合
0x02 逻辑回归(Logistic regression)
逻辑回归有些书上也叫“对数几率回归”,一般用它来解决一些二分类问题,所以它还有一个名字叫最大熵分类器(MaxEnt)。最近很火的深度学习,逻辑回归也是里面最基本的组成单元。它的Cost Function为:

下面举个例子
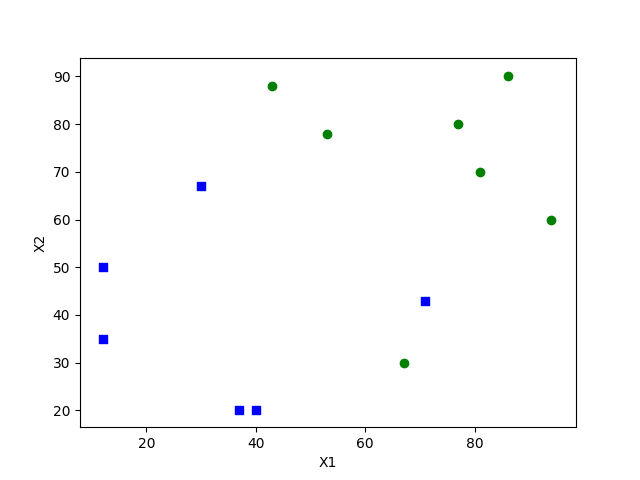
- 假设有个叫颜值系数F(0~100),F越大说明这个人长得越好看,那么它脱单的几率越高,反之就越低了,另外还添加一个幽默程度(0~100),同样越高说明这个人越有趣,越容易找到对象。为了拟合出这两个系数共同的影响因子,现在我们在某学校计院里面随即抽取了13个人,然后给他们取了编号分别为1~13,测量他们的颜值系数以及是否单身,情况如下:
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 颜值系数F | 40 | 30 | 81 | 66 | 43 | 94 | 37 | 77 | 67 | 12 | 53 | 12 | 86 |
| 幽默系数F | 20 | 67 | 70 | 90 | 88 | 60 | 20 | 80 | 30 | 35 | 78 | 50 | 90 |
| 是否有对象 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 |
我们定义下这些数据,画坐标轴上是一个这样的分布
from matplotlib import pyplot as plt
x1 = [40, 30, 81, 71, 43, 94, 37, 77, 67, 12, 53, 12, 86]
x2 = [20, 67, 70, 43, 88, 60, 20, 80, 30, 35, 78, 50, 90]
y = [0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 1, 0, 1]
fig, ax = plt.subplots()
datas = list(zip(x1, x2, y))
get_cord_x1 = lambda x:x[0]
get_cord_x2 = lambda x:x[1]
cord1 = list(filter(lambda x:x[2]==0, datas)) # 把两类数据分开
cord2 = list(filter(lambda x:x[2]==1, datas))
x1cord1 = list(map(get_cord_x1, cord1))
x2cord1 = list(map(get_cord_x2, cord1))
x1cord2 = list(map(get_cord_x1, cord2))
x2cord2 = list(map(get_cord_x2, cord2))
ax.scatter(x1cord1, x2cord1, c='blue', marker='s')
ax.scatter(x1cord2, x2cord2, c='green')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
我们使用Sklearn提供的LogisticRegressionModel进行训练:
from sklearn import linear_model
import numpy as np
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
X = np.array(np.mat(list(zip(x1, x2))))
clf.fit(X, y)
print(clf.coef_, clf.intercept_)
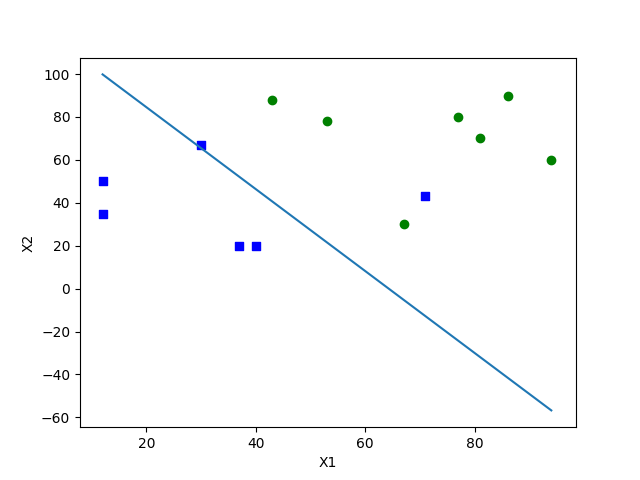
这里得到θ0, θ1, θ2 分别是-1.92, 0.03, 0.016。
我们把决策边界(θX=0)画出来如下图所示:
上面数据和例子只是为了配合实验造的,事实并非这样。而且事实上,找对象这个东西还有很多因素干扰着,并不是完全靠脸。
而且生活中很多问题也并非是只有两类,种类会很多,然而逻辑回归只能解决的是二分类问题。